 ChatGPTを業務で使いたい経営者が最初にやるべき「社内ルール作り」
ChatGPTを業務で使いたい経営者が最初にやるべき「社内ルール作り」
「ChatGPTを使いたいが、何から始めれば良いか分からない」——立ち止まる経営者たち
「うちの会社でもChatGPTを業務に使いたいんですが、何から手を付ければ良いんでしょうか」——経営者からの相談で、この質問を受ける頻度が確実に増えています。
そして、実際の現場ではこのような状況が並行して起きています。
- ベンダーから「とりあえず全社員に法人プランを配布しましょう」と提案されたが、本当にそれで良いのか判断できない
- 現場の若手社員が個人アカウントで業務に使い始めており、情報漏洩のリスクが頭をよぎる
- 経営層から「他社はどう使っているのか」と問われるが、表に出ている事例は成功例ばかりで参考にならない
- 「ルールを作ろう」とは思うものの、何を禁止し何を許容するかの線引きが見えない
- 法務に相談したら「全面禁止が最も安全」と返ってきて、議論が止まってしまった
問題は、ChatGPTそのものではありません。**「使い方の前提となるルールが社内に存在しないまま、なし崩しで利用が広がっている」**ことです。
そして決定的に厄介なのは、ルールを作らないまま放置すると、「禁止」と「黙認」のどちらに倒れても会社にとって損失が出る構造になっている点です。禁止すれば現場の生産性向上の機会を逃し、黙認すれば情報漏洩や著作権トラブルのリスクが確率的に積み上がっていきます。
「ツール選びより先にやるべきこと」を、多くの企業が飛ばしています
ChatGPTの業務利用で失敗するパターンには、共通する初動ミスがあります。それは**「ツール選定や契約プランの議論から入ってしまう」**ことです。
経営者の多くは、ChatGPT TeamやEnterprise、あるいはCopilotやGeminiといった製品比較から検討を始めます。しかしツール選びは、本来「自社で何をAIにやらせるか」「どこまでを許容範囲とするか」が決まった後にすべき意思決定です。前提となる業務スコープと許容範囲が定まっていない段階で製品を選ぶと、契約してから「あれもダメ」「これも禁止」と制限が増え、結局誰も使わない高額な契約だけが残ります。
そして社内ルールが無いまま運用を始めると、もう一つ深刻な問題が起きます。**「現場の判断にすべてを委ねる構造」**になってしまうのです。AさんはChatGPTに顧客情報を貼り付けても問題ないと考え、Bさんは社外秘のメールを要約させ、Cさんは契約書のドラフトを丸ごと食わせる——同じ会社の中で、同じツールに対して、まったく異なる利用基準が並列で動き出します。
この状態は、後から「実はあれは禁止だった」と告知しても巻き戻せません。一度入力されたデータがOpenAI側のシステムに学習データとして残るかどうかは契約形態によって変わりますが、「漏洩したかもしれない」という疑念は、社内のリスク管理上は事実と同じ重みで扱われるためです。
つまり、ChatGPTの導入で経営者が最初にやるべきは、ツールの選定でも全社展開でもなく、「自社で何をして良いか・何をしてはいけないか」を文書化する作業なのです。
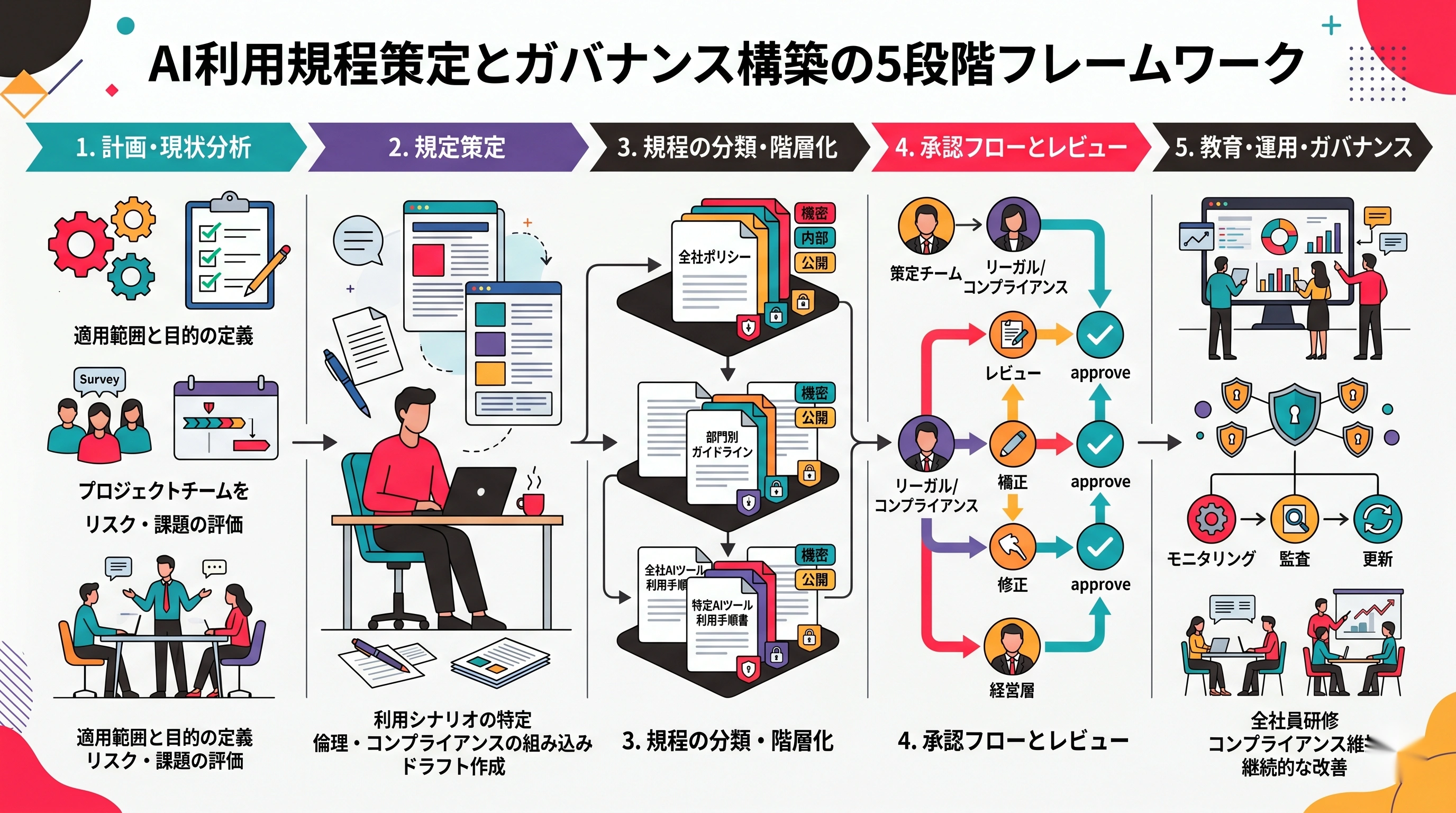
この記事で、社内ルールを作る5つの段階を整理します
本記事では、ChatGPTを業務利用するための社内ルール作りを、以下の5段階に分けて順番に解説します。
- 情報資産の分類——AIに入力して良い情報・絶対に入力してはいけない情報の線引き
- 入力禁止データの定義——具体的に何を「禁止」とするかの列挙
- 利用承認フロー——誰が・どの業務で・どう承認を得て使うかの設計
- ログ管理と教育——利用実態の可視化と社員教育の運用
- 違反時の対応と継続改善——ルール違反が起きた時の対処と、ルール自体の見直しサイクル
それぞれの段階で、すぐ自社規程に落とし込める雛形・チェックリスト・運用パターンを提示していきます。読み終えた段階で、「来週から自社で議論を始められる」状態を目指します。
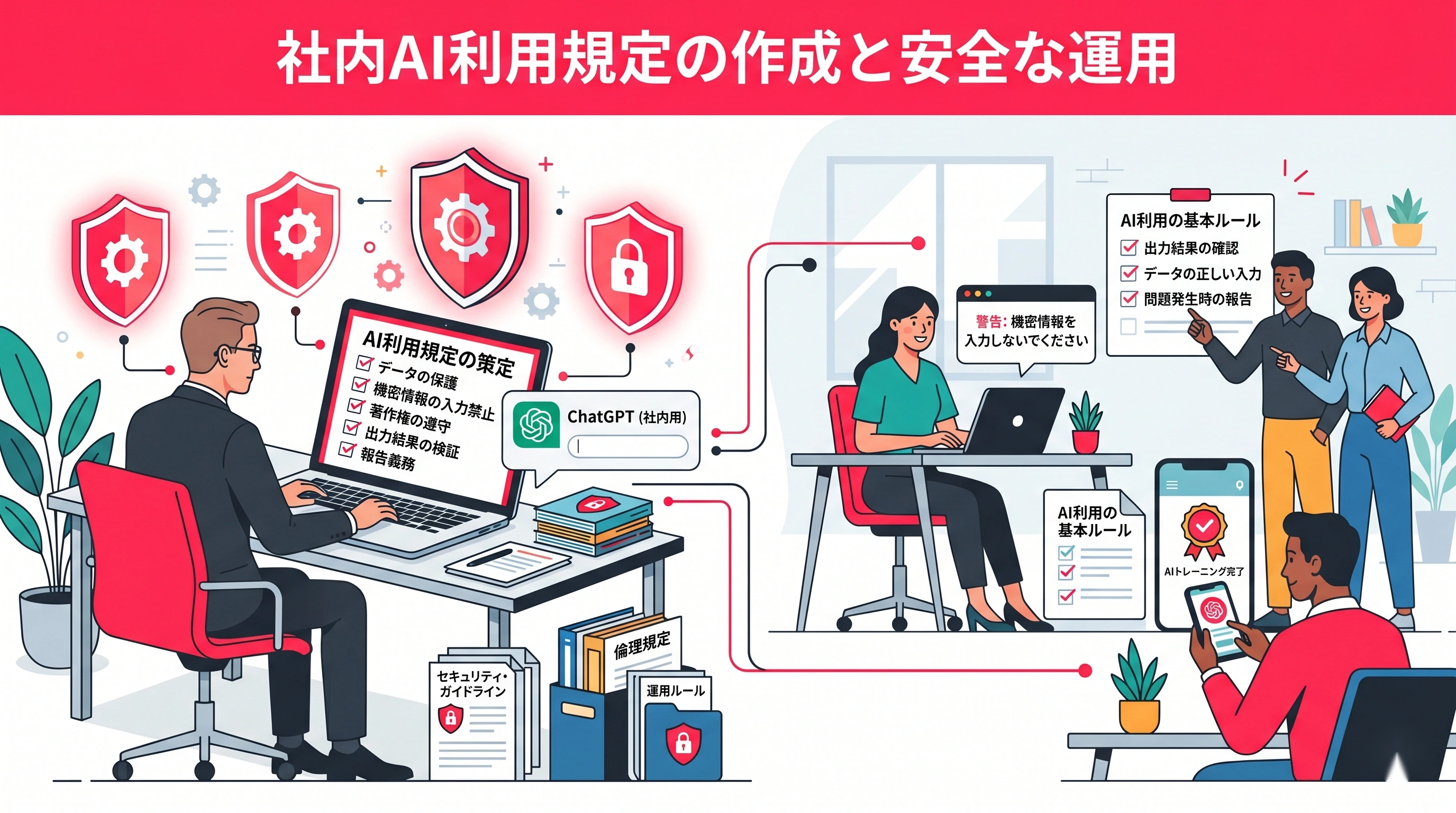
 ChatGPT業務利用ルールの全体構造を可視化した図
ChatGPT業務利用ルールの全体構造を可視化した図
段階1: 情報資産の分類——AIに入力して良い情報を3つに切る
ルール作りの最初の作業は、自社が扱っている情報を**「ChatGPTに入力して良いかどうか」の観点で分類し直す**ことです。一般的な情報セキュリティ分類(公開・社外秘・極秘など)とは別軸の整理が必要になります。
推奨する3区分
| 区分 | 内容 | ChatGPT入力可否 |
|---|---|---|
| グリーン | 公開情報・既に世に出ている情報 | 制限なく入力可 |
| イエロー | 業務用情報(社外秘ではないが内部利用が前提) | 条件付きで入力可 |
| レッド | 個人情報・機密情報・顧客情報・契約データ | 入力禁止 |
← 横にスクロールできます →
この3区分は、現場の社員が**「迷わず判断できる粒度」**であることが重要です。区分を5段階や7段階に細分化すると、判断コストが上がり、結局「分からないから使わない」か「分からないから使ってしまう」のどちらかに流れます。
グリーンの具体例
- 自社の公開Webサイトに掲載済みのテキスト
- プレスリリース済みの内容
- 一般公開されている法令・公的データ
- 社員自身が新規に書いた、社内外の誰の情報も含まないアイデアメモ
イエローの具体例(条件付き許可)
- 業務マニュアル・手順書(顧客名や社内固有名詞を伏せ字化した上で)
- 議事録の要約用テキスト(参加者氏名・取引先名を匿名化した上で)
- 社内向けの汎用的な企画書ドラフト(数字・固有名詞を抜いた骨子のみ)
イエローを使うには「入力前に伏せ字化・匿名化処理を必ず行う」というルールをセットで運用します。この一手間を制度化することが、後述するレッド情報の流出を防ぐ最大の防波堤になります。
レッドの具体例(絶対に入力しない)
- 顧客の氏名・住所・電話番号・メールアドレス
- 取引先の社名と紐付く契約金額・取引条件
- 社員の人事評価・給与・健康情報
- 未公開の財務データ・経営計画
- 開発中のソースコード・特許出願前の技術情報
- パスワード・APIキー・アクセストークン
レッド区分の判定で迷ったら、**「これがSNSに流出したら謝罪会見が必要か」**を基準に考えるのが現場で通用する判断軸です。謝罪会見が必要なレベルの情報は、すべてレッドに振り分けます。
段階2: 入力禁止データの明文化——「曖昧な禁止」が一番危険
情報資産の3区分ができたら、次は**「具体的に何を入力してはいけないか」を社内規程に明文化**します。ここを曖昧にしたまま運用を始めると、必ず事故が起きます。
よくある「曖昧禁止」の例
- 「機密情報は入力しないこと」——機密情報の定義が人によって違う
- 「業務に関係ないことは入れないこと」——業務関係の線引きが個人裁量に依存する
- 「常識的に判断すること」——常識の中身が世代・職種でばらつく
これらの表現は、規程としては書かれていても、現場では機能しません。**「具体的な単語レベルで列挙する」**ことが、明文化の最低条件です。
明文化テンプレート(雛形)
本規程において、以下のデータをChatGPTおよび類似の生成AIサービスに
入力することを禁止する。
【絶対禁止データ】
1. 顧客個人を特定できる情報(氏名・住所・電話・メール・生年月日)
2. 顧客企業の内部情報(取引金額・契約条件・取引先固有の業務手順)
3. 自社社員の個人情報(人事評価・給与・健康・家族情報)
4. 未公開の経営情報(決算前財務データ・M&A計画・新規事業計画)
5. 認証情報(パスワード・APIキー・アクセストークン・秘密鍵)
6. 開発中の技術情報(特許出願前の発明・未公開のソースコード)
7. 医療・法務・税務に関わる個別具体ケース
【入力時に伏せ字化が必要なデータ】
1. 議事録(参加者名を伏せ字化)
2. メール文面(差出人・宛先・固有名詞を伏せ字化)
3. 業務手順書(顧客固有の運用部分を一般化)
【入力可能なデータ】
1. 自社の公開情報・プレスリリース済みの内容
2. 一般公開されている法令・統計・公的データ
3. 社員自身が新規に作成した、固有名詞を含まない汎用テキスト
このような形で箇条書きで列挙し、現場社員が判断に迷ったときに辞書的に引ける形式にすることが重要です。
「グレー判断」のルールも明文化する
実務では、上記の3区分のどれにも当てはまらない判断に迷うケースが必ず出ます。そこで**「グレー判断のエスカレーション先」**もルールに含めます。
【判断に迷った場合】
1. 直属の上長に相談する
2. 上長が判断できない場合は情報システム部門に相談する
3. 情報システム部門が判断できない場合はDX推進担当役員に相談する
4. 上記いずれの判断も得られない場合は、入力しない
「迷ったら入力しない」を最終原則として明記しておくことで、現場の防衛行動を促せます。
段階3: 利用承認フローの設計——「全員自由」と「全員禁止」の間を作る
ルールができても、その運用フローが無ければ機能しません。よくある失敗は、「申請して許可を得る」と「自由に使う」の極端な二択で設計してしまうことです。
推奨する3層フロー
| 層 | 利用者 | 承認 | 利用範囲 |
|---|---|---|---|
| L1 | 全社員 | 不要 | グリーン情報の利用のみ |
| L2 | 業務利用申請者 | 部門長承認 | イエロー情報を伏せ字化して利用 |
| L3 | 高度利用者 | DX推進担当役員承認 | 業務システム連携・API利用 |
← 横にスクロールできます →
L1は申請不要にすることで、現場の手軽な利用を阻害しないのがポイントです。「ちょっとした文章校正」「公開情報の要約」程度の用途で承認フローを回すと、申請疲れで誰も使わなくなります。
L2は「定型業務でAIを反復利用したい」社員向けの層です。部門長が承認することで、業務適合性の判断と教育機会の付与をセットで行います。この層は**「3か月ごとに利用実態を見直す」**運用にしておくと、ルールが形骸化しません。
L3は基幹システム連携や顧客対応自動化など、影響範囲が大きい用途を想定した層です。役員承認を必須にすることで、リスク管理と投資判断を経営層に集約します。
「個人アカウント」は明確に禁止する
利用承認フローの設計で必ず明文化すべきは、**「個人アカウントでの業務利用は全層で禁止」**という条項です。法人契約のChatGPT TeamやEnterpriseでは入力データが学習に使われない契約条項が含まれていますが、無料の個人アカウントでは原則として入力データが学習に使用される設計です。
社員が「効率が良いから」と個人アカウントを業務に使い続けると、知らないうちにレッド情報がOpenAIの学習データに混入する可能性があります。これを止めるためには、**「業務利用は会社が契約した法人アカウントのみ」**を規程に明記し、定期的にアクセスログを確認する運用を組み合わせます。
段階4: ログ管理と教育——「ルールがある」と「ルールが守られる」は別問題
規程を作っただけでは、現場では守られません。ルールが守られている状態を維持するためには、ログ管理と教育の継続運用が必要です。
ログ管理で見るべき3つの指標
- 利用頻度の偏り——特定部門・特定個人だけが極端に多用していないか
- 入力文字数の急増——大量データを一度に入力する利用が発生していないか
- 利用時間帯の異常——深夜・休日の不自然な利用が発生していないか
これらの指標は、ChatGPT EnterpriseやTeamの管理者ダッシュボードで取得できます。**「定期的に見る人を決める」**ことが運用の最低条件です。情報システム部門の月次タスクに組み込み、異常値が出たら部門長にエスカレーションする流れを設計します。
教育の運用は「初回30分・四半期15分」が現実的
社員教育は、最初に30分の集合研修・eラーニングを設定し、以後は四半期ごとに15分の更新研修を回すのが運用負荷と効果のバランスが良い構成です。長時間の研修は受講率が下がり、短すぎると内容が伝わりません。
研修内容は以下の構成が機能します。
- 入力禁止データの3区分(10分)
- 実際の事故事例(業界他社の漏洩事案を匿名化して紹介、5分)
- 自社のレッド・イエロー・グリーンの判定演習(10分)
- 質疑応答(5分)
特に実際の事故事例は、抽象的な禁止ルールよりも記憶に残りやすく、現場の判断力を底上げする効果があります。新聞や業界誌で報道された生成AI関連の漏洩事案を匿名化して使うと、教材としても説得力が出ます。
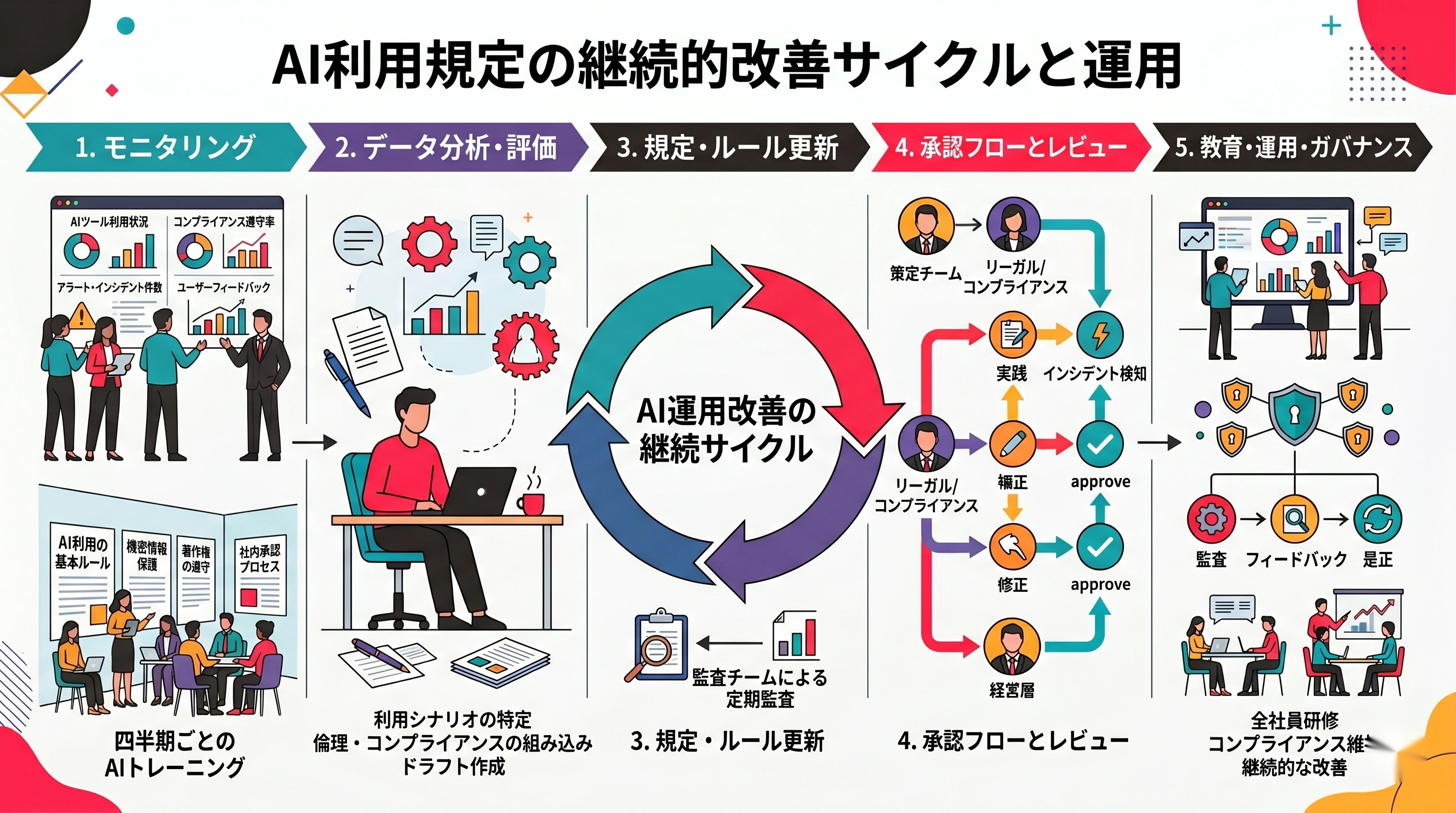 ルール運用と教育の継続サイクルを表した図
ルール運用と教育の継続サイクルを表した図
段階5: 違反時の対応と継続改善——「事故ゼロ」を前提にしない
ルールを作って教育を回しても、違反は必ず起きます。重要なのは**「違反が起きた時に何をするか」を事前に決めておく**ことと、ルール自体を継続的に見直す仕組みを持つことです。
違反時対応の3段階
| レベル | 状況 | 対応 |
|---|---|---|
| 軽微 | 伏せ字化漏れ・規程未読での誤利用 | 当事者教育・上長への報告 |
| 中度 | レッド情報の入力(影響範囲限定) | 利用停止・原因分析・全社共有 |
| 重大 | 顧客情報の漏洩・契約条項違反 | 法務対応・顧客通知・再発防止計画策定 |
← 横にスクロールできます →
軽微な違反を「叱責だけで終わらせない」のがポイントです。**「なぜ起きたか」「ルールのどこが分かりにくかったか」**を必ず聞き取り、ルール改定の材料にします。違反者を悪者にする運用は、現場の隠蔽体質を生み、結果的に重大事故の検知を遅らせます。
半年ごとのルール見直し
ChatGPTを含む生成AIサービスは、機能・契約条項・対応データ範囲が頻繁に変わります。社内ルールも半年に1回は見直す前提で運用設計します。
見直しのタイミングで確認すべき項目は以下の通りです。
- ベンダー側の契約条項に変更が無いか
- 自社の業務変化(新規事業・業務委託先の追加など)でレッド情報の範囲が変わっていないか
- 直近半年の違反事例から見えてきた「ルールの穴」が無いか
- 競合他社・業界他社の事故事例から学べる更新点が無いか
この見直しサイクルを止めると、ルールはあっという間に陳腐化します。「ルールを作ること」より「ルールを更新し続けること」のほうが運用上は重要です。
自社で全部やろうとすると、立ち上げに半年かかります
ここまで読んで、「やることが多すぎて、自社の人手では回せない」と感じた経営者は少なくないはずです。実際、情報資産分類・規程文書作成・教育コンテンツ整備・ログ運用設計を自社内製で進めると、立ち上げに半年から1年かかるのが一般的です。
その間にも現場では生成AIの利用が進み、ルール無き利用が既成事実化していきます。「ルール整備の遅れ」そのものがリスクになっている状態と言えます。
社内に専任のDX推進部門を置く負担を抑えつつ、ChatGPT利用ルールの整備を素早く進めたい場合は、外部の伴走型サービスを活用する選択肢があります。例えば月額制自社DX推進部のようなサブスク型の支援を使えば、ルール雛形の提供から教育コンテンツ整備、ログ運用設計までを月額固定で任せられるため、内製の人材リスクを抱えずに最短ルートで立ち上げられます。
こんな経営者・責任者におすすめです
- 社員がChatGPTを使い始めているが、明確なルールが社内に存在しない
- 法務や情報システムから「全面禁止が安全」と言われ、議論が前に進まない
- 規程を作りたいが、何をどう書けば良いか雛形が無くて困っている
- 教育やログ運用までセットで設計したいが、自社にノウハウが無い
- 「とりあえずルールを作る」のではなく、「運用が回るルール」を作りたい
特に**「現場が個人アカウントで使い始めている」**という状況は、すぐ動き出すべきサインです。気付いた時点でレッド情報が学習データに混入している可能性があり、その損害は事後に取り戻せません。
ルール整備は、生成AI活用の効果を最大化するための投資です。守りの整備が甘いまま攻めだけ進めると、必ずどこかで重大事故が起きます。逆に、ルールが整っている会社は、現場が安心して攻めの活用に踏み込めるようになります。
まとめ
 社内ルール作りで生成AI活用を加速させる経営者の姿を表した図
社内ルール作りで生成AI活用を加速させる経営者の姿を表した図
ChatGPTを業務で使うために経営者が最初にやるべきは、ツール選びでも全社展開でもなく、**「社内ルールの整備」**です。具体的には以下の5段階を、この順番で進めます。
- 情報資産の3区分——グリーン・イエロー・レッドで判断軸を作る
- 入力禁止データの明文化——曖昧な「機密情報禁止」では機能しない
- 3層の利用承認フロー——全員禁止と全員自由の中間を設計する
- ログ管理と教育の継続運用——半期ごとの教育と月次のログ確認
- 違反対応とルール見直し——半年ごとの更新サイクルを前提にする
ルール整備は地味な作業です。しかし、この土台が無いまま生成AI活用を進めると、ある日突然「うちの顧客情報が学習データに残っているかもしれない」という事態に直面することになります。そして、その事態は事後対応では取り戻せません。
自社だけでルール整備を進めるのが難しい場合は、外部の知見を借りることを検討してみてください。生成AIの社内ルール策定から運用設計までを月額制で伴走する月額制自社DX推進部に、まずは現状の利用実態の棚卸しから相談してみるのが、最短で安全な活用に至るルートです。守りを固めてから攻めに転じる——それが、生成AI時代の経営者の正しい初手です。


